
1. はじめに
こんにちは。LeapWell の菊田です。
近年、Azure AI Search をはじめとするパブリッククラウドのマネージドサービスや、LangChainやDifyなどのオープンソースソフトウェア(OSS)を利用することで、RAGアプリケーションの構築が非常に容易になりました。
ますます多くの企業でRAGの利活用が進んでいくでしょう。
本記事ではRAGの運用について書こうと思います。
構築は容易に行えても、本番環境でアプリケーションをリリースする際には運用設計(MLOps、Machine learning operations)はじっくり考える必要がある点は変わりません。
運用の設計ができていないと、エラーやレスポンス速度の問題を特定・改善することや、ユーザーのフィードバックや自動評価の指標を活用して継続的に改善を行うことが難しくなり、RAGの想定外の挙動や低精度に気がつくことができず、ユーザーの信頼を失ってしまう可能性があります。
本記事では運用の中でも、オンライン評価に焦点を当てて書きます。
オンライン評価自体について説明した上で、方法論やツールについても紹介します。
本記事のゴール
本記事ではオンライン評価について、以下を理解するために書きます。
- オンライン評価とは何か / なぜ重要なのかを理解すること(2章)
- オンライン評価の方法を理解すること(3章)
- オンライン評価の具体的なツールを理解すること(4章)
対象読者
本記事の対象読者は、LLMの構築はできても本番運用に不安がある技術者や、運用時の論点を知りたい非技術者です。
なお、前提としてLLMはOpenAI等で提供されているChatGPTなどの基盤モデルを想定し、モーダルは自然言語に限定して書きます。
2. RAGにおけるオンライン評価
オンライン評価は本番環境でユーザーが利用しているアプリケーションに対する評価のことを指し、MLOps分野の一つ(継続的評価とも呼ぶ)として機械学習を搭載したアプリケーションでは重要視されています。
例えば社内ドキュメントを使ったチャットボットを例にとると、本番のシステムにてユーザーがした質問に対してボットが適切な回答を返しているのか?や想定通りのスピードで返せているのか?を監視することがオンライン評価です。
構築時にも人間による定性評価や後述する自動評価などで、RAGの性能を確かめると思います。
これをオフライン評価と呼びます。
ただし長くアプリケーションを運用していくにあたって、ユーザーの使い方やクエリが変わったり、RAGのバックエンドのデータベースに予期しないデータが入ったりするなど、構築当初は考えていない想定外が起こることがあります。
機械学習のモデルはインプットデータに依存してアウトプットが決まること、そして想定外を事前に想定することには限度があることから、本番運用中でも監視をしていくことが必要になります。
オンライン評価ができていないと、想定外が起きても開発者が気がつくことができず、ユーザーからのクレーム、ひいてはサービスからの離脱に繋がってしまう可能性があります。
3. 具体的な方法論
オンライン / オフライン評価に限らず、RAGを評価するにはLLMによる自動評価と人間評価があります。
人間評価は名前の通りRAGのアウトプットを人間が評価する方法であり、自動評価は人間を介さずにLLMなどで自動的に評価する方法です。
自動評価の中に Ragasなどの汎用指標とアプリ固有の汎用指標があり、どのような方法を取るかはアプリの性質によって異なります。
本記事では、それぞれの説明とそれぞれをどう使うべきかを記述します。
人間評価
名前の通り人間がRAGのアウトプットに対して、Good or Bad で評価するイメージです。
開発者が定期的にサンプリングをして評価をすることもできますし、ユーザーに提供する画面の中に表示してユーザーに直接フィードバックしてもらうことも可能です。
人間評価のメリットデメリットは以下になります。
メリット
- 比較的正確に評価できる
- 感情的に良さそう・良くなさそうなど定性的な側面を含めて評価できるため、ユーザー目線に近い評価ができる
デメリット
- 人間が評価するため、工数がかかる
- 全数チェックができないため、問題に気がつかない可能性がある
自動評価
自動評価はLLMを用いてRAGのアウトプットを評価する手法です。
方法としては、Ragasなどの汎用的なRAG評価指標の利用や、アプリケーションに応じたカスタム評価指標の利用(例えば F1スコアなど)を利用することが考えられます。
Ragasについては後述します。
自動評価のメリットデメリットは以下になります。
メリット
- 人間の手を介さないため効率的に評価できる
- 主観が入らないため一貫性のある評価ができる
デメリット
- 人間の直感や感情的な評価ではないため精度が劣る
- テストの実行にLLMを叩くことによるAPIコストがかかる
人間評価と自動評価をどう使うべきか
私見も踏まえて人間評価と自動評価をどう使うべきかを考察します。
上記で示した通りどちらもメリットデメリットがあり、どちらをどの程度使うべきかはアプリケーションの性質に依存するため、トレードオフを見極めた上でどちらもデメリットが響かない程度に利用するのが良いと考えています。
一つの指針としては、ユーザーによるフィードバックをシステムで受け取ること、開発者によるサンプリングした結果を定期的に人間評価すること、LLMによる自動評価を高頻度・大半のデータに対して行うことがバランスが取れた選択肢になると考えています。
まずユーザーからの率直なフィードバックはサービスの価値にもつながるため非常に重要であり、フィードバックを任意にすればユーザー負担の増加は限定的です。
RAGのアプリケーションを運用する際には、MUSTの機能として実装するのが良いでしょう。
実際RAGではありませんが、ChatGPTにもユーザーフィードバックを行う機能は実装されており、GPT-4, GPT-4o などを構築する際に役立てられていると思われます。
なお、ユーザーフィードバックは一定のバイアスがかかることには注意が必要です。
サービスへの期待値が高いユーザーは投稿するが、大半のユーザーは投稿しないと考えられるためです。
その点は分析時には注意が必要でしょう。
開発者によるサンプリングの評価ですが、ユーザーの大半はフィードバックをしないと考えられることや、安心感を持った運用につながることから必要と考えています。
1週間に1度100件のアウトプットを開発者が見る程度であれば、工数の増加に対して安心感が得られるなどの効果が大きいでしょう。
Slackで自動通知したり、リリース後大きな問題がなさそうであれば徐々にサンプル数を減らしていくなどすれば負担を減らしながら運用することができます。
自動評価については、実行コストがかかる考慮は必要ですが、近年LLMの実行コストは下がっていることや、人間の工数と比べると明らかに安価であること大半のデータに対して毎度実行するのが良いと考えています。
後ほど紹介するRagasで評価をすれば、Retrieval と Generation の精度を分けて評価することで問題の分解・ボトルネック特定、改善点の集中の意思決定に役立てることができます。
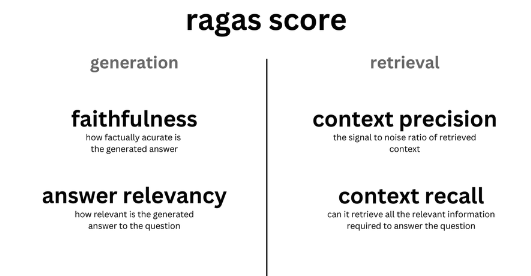
Ragas
Ragas(Retrieval-Augmented Generation Assessment System)は、RAGパイプラインの評価を行うためのフレームワークです。
アルゴリズムの詳細についてはまた別の機会で書こうと思いますが、ざっくり「GenerationとRetrievalの精度を別々に自動測定できる」と理解しておくのが良いと思います。
アウトプットの生成結果に対して評価ができるだけでなく、 context がユーザークエリに対して適切かを評価することができるため、Retrieval と Generation のどちらが悪いのか問題分解することができるのが大きな特徴と考えています。
Ragas は Github にてアルゴリズムや使用法が公開されているため、誰でも簡単に利用することができます。
具体的な評価指標としては、Generationに関してFaithfulness やAnswer Relevancy 、Retrievalに関しては Context PrecisionやContext Recall が代表的ですが、そのほかの指標についても定量的に自動評価を行うことが可能です。
Ragas は RAG の精度評価を指標を分けて測定することによって、一定信頼できる結果を返してくれる印象があります。
ただし、自動評価の性質上、精度は100%にはならず人間の精度評価には劣ると考えておいた方が良いでしょう。
人間評価と併用する形で使うのが良いと思います。
4. 具体的なツール LangSmith
オンライン評価の具体的な方法がわかったところで、それらを簡単に行えるLangSmithについて紹介します。
LangSmithは LangChainの開発元がリリースしている汎用的なLLMOpsツールであり、本番環境でのアプリケーションの監視を目的とするツールです。
本記事ではオンライン評価に対して焦点を当てますが、そのほかにも実行のトレース機能やデバッグ機能、データセット構築機能などがあり大変便利なツールです。
SaaSとしても提供しているので簡単に試すことができますし、2024年5月にはSelfHostすることが可能になりましたのでセキュリティ的にデータを海外に出せなかった会社にも利用可能なツールです。
LangSmithでは、Ragas に基づいたLLMによる自動評価を行うことや、ユーザーフィードバックAPIを提供すること、開発者による管理UIでの人間評価も可能であるため、3章で紹介した方法を簡単に実現させることができます。
LangSmithの具体的な設定方法や使い方については、『LLM アプリケーションのデバッグ、テスト、評価、監視するプラットフォーム LangSmith が公開!!』や『LangSmithの概要と使い方【LLMOps】』、など優れた記事があるので詳細はこれらの記事に譲ろうと思います。
最後に
最後までお読みいただき、ありがとうございました。
本記事ではRAGの精度監視の必要性と具体的な方法論について記載しました。
お役に立てると嬉しいです。
LeapWellでは RAGの導入や導入後の技術フォローを行う技術パートナーサービスや、生成AI関連の開発を伴走開発するコンサルティング開発サービスを提供しています。
具体的なご相談あれば、お気軽にお問い合わせいただけると幸いです。
AIやデータ基盤構築でお悩みの方、お気軽にお問い合わせください。
