

はじめに
AI開発企業のLeapWellで働いている伊藤です。
最近生成AIの波が強まっています。自社特化のLLMを作る企業も多いと思います。ただ具体的に自社に特化させるにはどうしたらいいか?というのは開発経験がないと難しい論点だと思います。本記事では、非開発者の方向けに、自社特化LLMを開発する際わかっておくべきエッセンスを直感的かつわかりやすく抽出しました。
本記事は特化LLM開発経験を持つ筆者が、論文/英字記事など最新情報を元に記載しているため一定トレンドを抑えた意見だと思います。ただしあくまで執筆時点(2024年2月)の情報なので、一意見として参考にしてください。本記事では、自社特化LLM開発の主要2手法であるRAG(Retrivevial Augument Generation)とファインチューニング(Finetuning)について取り上げます。また実装方法を調べている開発者の方も、本記事読了後の方が実装イメージが沸きやすいと思います。
時間がない方のために考察の結論部分だけ記載します。Microsoftが2024年に出した論文では総合的にRAGの方が優勢ですが、その結論だけを技術的特徴の理解なしに盲信するのは危険です。技術的特徴について言及すると、追加情報からマニュアル的に事実のみを回答する人間が欲しい場合は、RAGが向いています。ただし、追加情報を理解した上で自分の意見を行って欲しい場合は、ファインチューニングの方が向いています。最低でもこの技術的特徴を理解するだけでも、多くの判断がしやすくなるでしょう。
1. ChatGPTの登場
ChatGPTは2022年11月にOpenAI社が開発したサービスであり、公開後2ヶ月でユーザー数1億人という異常なスピードで拡大し、あっという間にビジネスに革命をもたらしました。非常に高い精度で、まるで人間のような回答ができるこのサービスに多くの人が、その高い利便性に興奮と恐怖を感じたと思います。
多くの企業はChatGPTのトレンドの波に乗り遅れないように、生成AIの適応に本腰を入れ始めました。その応用範囲は広く、FAQやチャットbotなど多くのサービスが現在立ち上がっています。しかし、ChatGPTも完璧ではなく多くの欠点を持っているため、実サービスでそのまま利用するのは難しいです。
2. ChatGPTの欠点
ChatGPTは、非常に頭の回転が速く、古今東西の広範な知識を持った人物と言えるでしょう。競馬のルール説明から、マーケティングのコピーライティングの案出しまで、多くの要望に対して、適切に回答を返していきます。ただし、ChatGPTが今まで学習してきたデータの特徴上、どうしても苦手分野が発生してしまいます。苦手分野は様々ありますが、現在主流なものは2つ。一つはアップデート性の欠如、もう一つは信頼性の欠如です。
2-1. アップデート性の欠如
AIを構築するには、教師データという大量のビックデータを学習させる必要があります。教師データから学習した内容が、AIの各種変数に組み込まれていくためです。これは人間が学習する仕組みとほとんど同じです。ただし、人間と異なるのは学習データ自体は外部から与える必要があるということです。そのためChatGPTはどうしても新しいデータへのアップデート対応が遅れてしまいます。「2024年の日本の総理大臣は誰ですか?」と聞いても、人間のように自分でニュースを見れるわけではないので、どうしても回答できません。いくら賢くても情報がなければ、正しく回答することはできないのです。
2-2. 信頼性の欠如
ChatGPTはたまに幻覚(ハルシネーション)と呼ばれる嘘をつく現象を起こします。賢いChatGPTでも、情報がないことについては当然回答ができないです。ただ、ChatGPTは賢すぎるが故に、情報がない中でも類推と予想を立て、もっともらしい回答を生成できてしまいます。これが「幻覚」と呼ばれる嘘の情報です。例えば「東京都恵比寿駅にあるおいしい和食屋さんを教えて」と尋ねると、実在しない店舗を紹介することがあります。ChatGPTの賢さは、どんな質問に対しても、それっぽい回答ができてしまうがゆえに、一部嘘が混ざってしまい信頼性が担保しづらいという問題があります。
2-3. 対処方法
アップデート性、信頼性の欠如は悪意によって発生しているわけではなく、現段階でのAIの技術の構造上どうしても発生してしまう問題です。ただしChatGPTを活用したサービスを提供する側としては、この欠点はそのまま放置できるほど小さな問題ではありません。ただ、幸いにもこれらの欠点に対して打つ手がないわけではありません。どちらも「現段階の学習内容では、質問内容に関する情報を保有していない」という共通の構造上の問題に起因しています。そのため特定タスクに特化したLLMを作成したい場合、そのタスクに関連する情報を新たに学習させるという方法論でこの問題は解決できます。現在この方法論は大きく2つあります。RAGとファインチューニングです。
3. RAG / ファインチューニングの登場
RAGとファイチューニングは特定タスクに特化させるために「新しい情報」をChatGPTに与える方法論です。RAGは(Retrieval-Augmented Generation)の略であり、外部の知識ソースから事実を検索させて、その上で回答を生成させる方法です。対して、ファインチューニングはLLM文脈以外でもよく用いられる手法で、ChatGPTの様な汎用的なAIモデルに対して、特定タスクへの追加学習を与える方法です。どちらの方法論も追加した「新しい情報」が、特定タスクに回答するのに十分に専門的かつ最新の情報であれば、上記のアップデート性/信頼性の問題を解決できます。
3-1. Microsoft(2024)の論文の結果と直接応用の危険性
ではRAGとファインチューニングはどちらの方が解決策として優れているのでしょうか?結論としては、現時点では総合的にはRAGの方が若干優勢な模様です。Microsoftが2024年に出した論文「Fine-Tuning or Retrieval? Comapring Knowledge Injection in LLMs」によると、LLMの性能を評価するベンチマークの一つMMLU(Massively Multilingual Language Understanding Evaluation) Benchmarkを含めた複数指標で評価したところ、総合的に一貫してRAGの方が成績が良かったそうです。ただし、技術の中身を理解せずにこの結論をそのまま受け取るのは危険です。理由は大きく2つあります。
3-2.危険な理由1:タスクが大きく異なるかもしれない
1つめの理由は、総合的に「優れているか」どうかと、自社固有の状況やタスクを加味した上で「優れてるか」どうかは別問題だからです。LLMが「優れている」という評価基準は実現したいこと等で大きく変わると思われます。MMLUタスクであればRAGの方が優れているのは事実ですが、他のタスクの場合はそうとも限りません。また実際にAI開発することや、学習までかかる時間、データ作成コストなども考慮すると、一貫してRAGの方が優れているというのは暴論になってしまいます。
3-3. 危険な理由2:短期トレンドかもしれない
もうひとつの理由は、AIの技術的進歩は非常に凄まじく、現時点の結論はちょっとした技術進歩でひっくり返り得るからです。RAGもファインチューニングも現在研究が進み続けている発展途上の領域です。ChatGPTもいつまでも同じ性能ではなく、次々と最新モデルを出し続けています。この現状を考えると現時点の結論は、あくまで短期的なトレンドである可能性が高く、どちらか一方の手法の理解を切り捨てるのは中長期で見て危険です。
3-4. 「技術的特徴」と「導入時の判断軸」の2観点
以上の理由を踏まえると、どちらを取り入れる方が良いかは、ケースバイケースかつ今後の技術進歩に依存するという回答にならざるを得ません。これは全てのAIの技術の導入時の問いについて言えることでしょう。ただこれではあまり回答になっていません。
では一体どうしたらいいのでしょうか?AIの様なトレンドの早い新技術を学ぶ際に重要なのは「結論」を学ぶことではありません。一番重要なのはあまり短期的なトレンドに惑わされずに「技術的特徴」と「導入時の判断軸」を学ぶことです。そのため次はRAGとファインチューニングのそれぞれの技術の本質的特徴の説明と、実際の導入時の判断するときの考え方をお伝えします。
4. RAG / ファインチューニングの技術的特徴
LLMの特徴を掴む時には、何かわかりやすい別事例に置き換えて考えるとわかりやすいです。LLMはAI(人工知能)の一種です。そのため「人間」に置き換えて考えるのが、有効な方法の一つです。そのため本記事でも人間に置き換えて、RAGとファインチューニングの特徴を説明してみようと思います。前提として現在OpenAI社が提供しているChatGPTを人間に置き換えると「リリース時点でのネット上の情報について広範な知識がある、非常に賢い人間」と言えます。もっと平易にいうと「2023年1月から現代にタイムスリップしてきた東大生」だと考えてみましょう。(以下ではTくんとします)
※ChatGPT 3.5 Turboを想定、現状GPT4でファインチューニングはできないため。
4-1. RAGの技術的特徴
RAGとは、Tくんにマニュアルを渡した上で回答させている状態と同じです。質問内容がTくんが渡したマニュアルから判断できそうな内容であれば、回答可能と言えるでしょう。Tくんは十分に賢いので与えられたマニュアルの中から、質問に関係しそうな箇所を自力で探し、その新事実を元に回答します。RAGの中でも手法が分化しているので一概に言えませんが、基本的にはプロンプトを与えた際、マニュアル内から関連度高い箇所を自ら検探し、その検索内容をさらにプロンプトにはっつけた上で改めて回答を始めるということが、RAGが技術的に実施していることです。
<<図表1:RAGの仕組みのイメージ例 >>
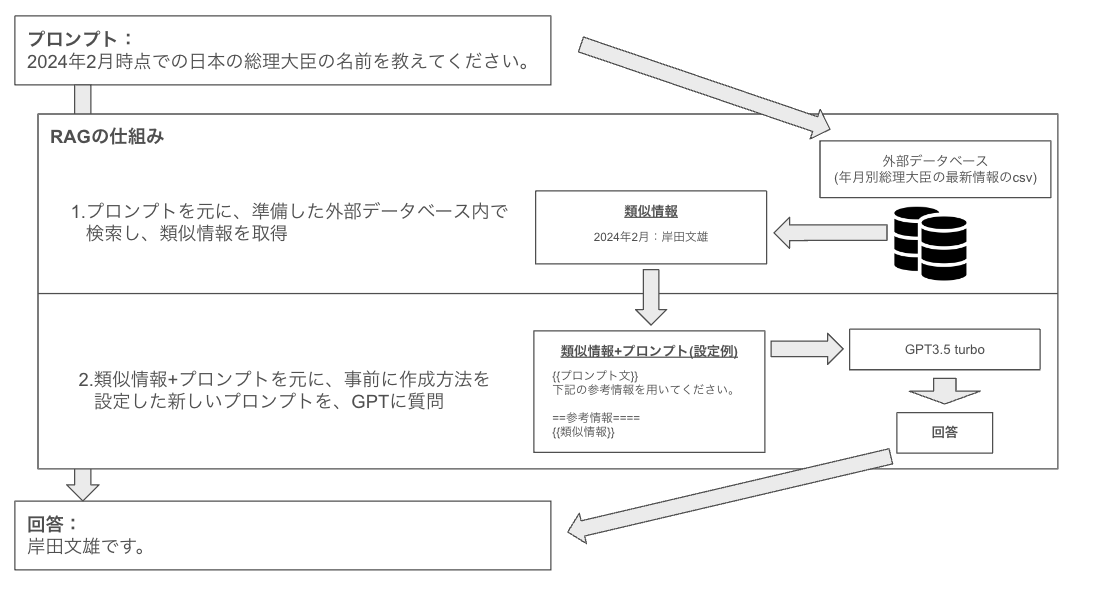
RAGは一見すると最適解ですが、明確な欠点もあります。誰もTくんにマニュアルについて教育してあげてないことです。つまりTくんはマニュアルを参考に関連がありそうなところを探索して回答しているだけであり、マニュアルの中身までは理解していません。いうなれば、ただオウム返しをしているだけです。いくら賢くても、新卒にマニュアルを渡せば勝手に仕事ができる様になるわけではありません。一からこういう場合は正解だよ、こういう場合は失敗だよと教育して、Tくん自身の経験として昇華させてあげないと、Tくん自身の言葉にはなりません。そこでファインチューニングの出番です。
4-2. ファインチューニングの技術的特徴
ファインチューニングは、T君に新しい知識に関する研修をOJTで経験させてあげることと同じです。研修用の問題集を準備した上で、問題集を学習する時間さえ与えてあげれば、T君は自分で頑張って学習します。T君は十分に賢いので、今まで人生で学習してきたことと照らし合わせながら、新しい知識を習得していきます。RAGではT君はマニュアルを参照してるだけなので、Tくんの知能自体は変わらないですが、ファインチューニングではT君は研修を経て自分の経験として昇華しているため、Tくんの知能自体も特定タスクに向けて変化します。
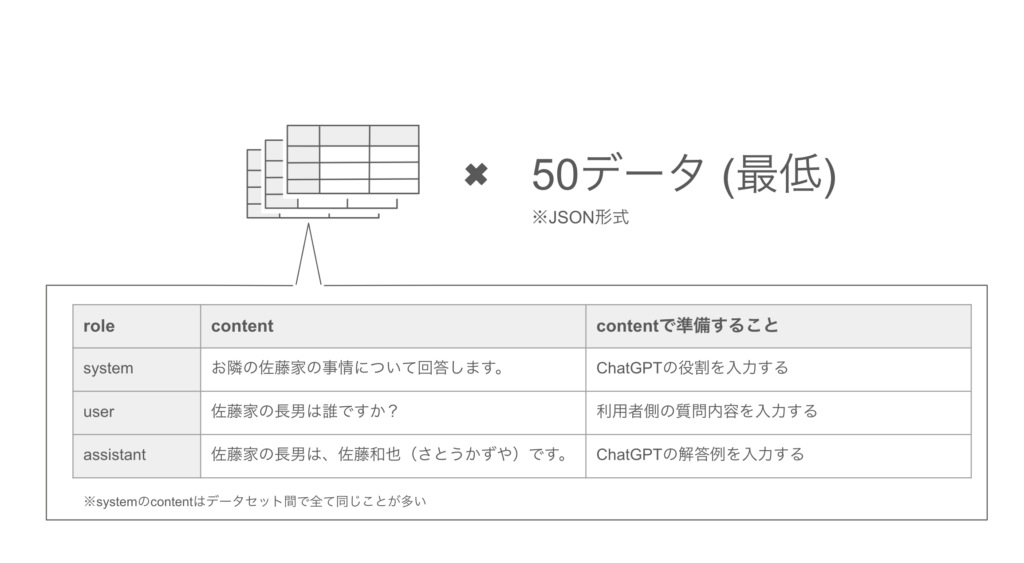
ファインチューニングの一番大変な点は、OJT研修の問題集の作成と、学習時間と費用という手間暇をかける必要があることです。具体的にはOpenAI社の公式サイトを見ると、具体的には写真の様な< 役割 / 質問 / 回答 >の学習データのセットを、最低でも50個準備することが推奨されています。さらにこれを作れば終わりではなく、実際に学習させて結果を見ながら、精度を上げるために様々な調整と手間をかける必要があります。また学習にも一定の時間と費用がかかります。
<<図表2:準備するデータセットのイメージ >>
以上が技術の抽象的な説明です。技術の本質的特徴を理解したと思いますのでいよいよ、結局自社ではどう判断すればよいのか?について記述します。
5. 導入時の判断軸
RAGを導入するべきか?ファインチューニングを導入すべきか?は複合観点で判断する必要がある総合的な問いです。そのため単一指標で簡単に結論を出すことは危険です。ここでは判断する際に、絶対に押さえておくべき論点について述べていきます。具体的には、1.) 特化させたいタスク、2.) 開発リソース、3.) 技術的資産 の3つの論点でお話しします。
5-1. 特化させたいタスク
RAGとファインチューニングはその技術特性上の違いから、それぞれ得意/苦手なタスクがあります。抽象化すると「事実」を学習するタスクはRAGが、「形式」を学習するタスクはファインチューニングが適しています。
「形式」の学習とは「らしさ」の学習と言えます。例えば「シェイクスピアの文体の様な表現で回答して欲しい」というタスクならば、ファインチューニングが適しています。この「らしさ」という概念は事実ベースではないため、マニュアル化しがたい領域だと思います。自社のMissionや、芸能人などの特定の人物らしさが詰まった回答をするチャットbotを作成したい場合は、ファインチューニングの方が妥当と言えるでしょう。
対して「事実」の学習はRAGに軍配が上がります。Anyscaleのブログのある実施した実験が有名です。こちらの実験ではシェイクスピアの脚本において「ロミオ」を「ボブ」に置き換えたデータセットをファインチューニングで学習させました。実験結果は「ロミオ」を「ボブ」に置き換えるという新事実の学習は難しいというものでした。例えば「ジュリエットは名前が B で始まる人に恋をしていました。彼の名前は?」という質問をすると「バナーディン」「ベンヴォーリオ」など元々の脚本のBで名前がはじまる登場人物について回答してしまいます。
こういう場合は「ジュリエットの恋人はボブです。」というマニュアルを用意して、RAGの手法で回答させた方が良い結果に繋がりやすいです。試しに図表3のように、ChatGPTのプロンプトに参考情報を追加すると、無事ボブを恋人として回答します。FAQや自社データベースから参照など、事実ベースのタスクであれば、基本的にはRAGを採用するべきでしょう。
<<図表3:RAGの手法で「ジュリエットの恋人がボブ」と回答させる例 >>

ではなぜRAGは事実に強く、ファインチューニングは形式に強いのでしょうか?ChatGPTのモデルの中身が公表されてないのと、結果論なので私見的考察が限界ですが、人に例えるとわかりやすいかもしれません。
RAGはマニュアルを読んでいるだけであり、T君の思想、考えそのものを述べてるわけではありません。現代文の問題の様に、意見を言うのではなく、参考情報ベースの回答をしているだけです。それに対してファインチューニングはT君が新しい知識を学んだ結果、改めてT君がどう感じるかの意見を聞いています。そのため、既存の体系と大きく矛盾してしまう知識だと、いままで学習してきた内容の方が優先されてしまいます。T君の倫理観/常識に反する知識をファインチューニングで学んでも、マニュアルとして回答はできますが、自分の意見として発することができないのです。
ジュリエットの恋人の実験も同じ結果を示唆しています。ジュリエットに「ボブが自分の恋人です」として回答してもらう方法は2つです。方法1はRAG的に回答してもらうことです。つまり、あくまでロミオを愛した状態のままで、「ボブが自分の恋人である」というマニュアルを読んでもらうことです。方法2はファインチューニング的に学習させる方法です。この方法ではボブと濃密な日々を過ごさせることが重要です。十分な期間と愛と労力を捧げれば、ジュリエットはロミオを忘れるくらいボブに好きになり、心から「ボブが自分の恋人である」と回答するでしょう。
5-2. 開発リソース
開発リソースは両方法で大変な部分が異なります。開発リソースを、前半のデータの準備、後半のコードの作成の2プロセスに分割した場合、前半部分がファインチューニングでは特に大変なためです。ファインチューニングの場合は最低でも50個の回答集をJSON形式で作成する必要があります。またあくまで最低50個であり、学習した結果が悪ければ更なるデータの準備や工夫が必要なケースが多いです。既にマニュアルや文書が何かしらの形である場合はRAGの場合、新たにデータセットを作る必要が少なく、はるかに簡単でしょう。ただし外部の知識ソース(マニュアル)自体の情報が、専門性、情報粒度、関連度等で問題がある場合は、データセットを作る必要が出てくるのでファインチューニングとあまり労力は変わらないです。
後半のコード作成についてはケースバイケースで、RAGの方が大変な場合もあります。一般的にはRAGの場合は大きく3つの機能をコードで記載する必要があります。3つの機能とは「外部データソースを文字列の塊に分割する機能」「質問内容と関連度が高い文字列の塊を見つける機能」「その内容を踏まえてプロンプトを変更する機能」。各種機能については、それぞれ様々なライブラリがあるため、一から開発する必要はあまりないですが、それらを組み合わせて一貫性を持たせるためには、一定の専門性を持った開発人材が必要です。コードに関しては、ファインチューニングの方は公式サイトに従うだけなので楽でしょう。ただしファインチューニングの場合は学習自体に費用とか期間というコストも追加でかかります。1000トークンあたり0.008ドル必要なので、利用料金が気付かぬうちに高額にならないよう注意する必要があります。
5-3. 技術的資産価値
基本的には他社模倣性の低さという観点で議論した場合、ファインチューニングの方が資産価値は高いでしょう。ファインチューニングされたT君は、学習させるというコストを払ってる分、他社が再現するのは難しいです。具体的には、問題集の準備という労力と、完全な学習後のT君の再現は不可能であるという2点が模倣障壁になっています。対してRAGの方はコード作成は技術的優位性が低く、本質的にマニュアルそのもの以外の技術的価値は低いです。そのため特化タスクのビジネス価値が同じだと仮定すると、模倣難易度の高さから、ファインチューニングの方が技術的資産価値は高いと言えるでしょう。
5-4. 実際に取り入れる場合
以上が判断時に押さえておくべき、3つの論点になります。これらの論点を踏まえた上で自社としてRAGとファインチューニングのどちらを取り入れるか判断することを推奨します。また実際に開発する際は、どちらか一方しか選べないわけではありません。まずはRAGから試して、うまくいかなかったらファインチューニングしてみたり、RAGとファインチューニングを組み合わせるなどといった手法もあります。完全なる二者択一という訳ではないので、手法の方も柔軟に考えることをお勧めします。
ここまで記事を読んでいただきありがとうございました。
※記事に対する感想があれば、tatsuya.ito@leapwell.co.jp あてまでご一報いただければ大変嬉しいです。
AIやデータ基盤構築でお悩みの方、お気軽にお問い合わせください。
